Available Scouting Tools
There are numerous online scouting tools available online. However, very few (if any) are truly free in a monetary sense, with most tools employing a subscription-based system. For example, Wyscout has a Bronze / Silver / Extra tier system, with the Bronze subscription starting at 250 euros/year. In this subscription model you can view match clips (50min max/month), and have access to stats and a customized PDF report / month.
On the other hand, Smarterscout is a cheaper alternative, with the lowest tier starting at ~$10/month, however it lacks the video capability of Wyscout (only stats). In this tier, Smarterscout also gives you 25 credits / day to search for players – 1 search = 1 credit. You can subscribe to a more expensive model, which will cost you ~$100/month, but you will have access to 55 leagues (with unlimited credits) instead of 36 as is the case for the lower tier, or you can buy their entire database for $300/month.
There is also Scoutpad, which also has a tier-based system, starting from $0/month (free, but incredibly limited in usage), to $11/month (for scouts/coaches), $25/month (professional scouts/analysts), and team-wide (most expensive, unlimited access to the system, pricing upon request).
Data, Data, Data
Of course, what these services sell is not only a nice user-interface and the possibility to organize your player data in an easier fashion, but also data. Lots, and lots, and lots of data. For example, Wyscout has data on 550,000+ players and teams. Smarterscout has data on players from 55 leagues, with even more available for private users. Scoutpad has curated data on over 200,000 players and over 7,000 teams, from 500 different competitions.
Of course, then, the pricing makes sense. Collecting, storing, and curating all that data is expensive, as well as adding additional data in a timely fashion each week. Server costs, employing people to collect data, data analysis team etc.
Open-Source Information
In this new subscription-based economics model, where companies gather data from you and then they sell it back to you, how can we ensure that we have access to accurate, open source data?
To our help comes SportsReference. Founded in 2000, SportsReference runs statistics websites on a variety of sports, including basketball, (American and European) football, and hockey. They have collected and curated huge swathes of data (both standard and advanced), which is freely available for anyone to use. For example, the fbref.com website (which I almost exclusively use in my analyses. Note: I am in no way affiliated with the website or owners) has gathered and curated data from over 180,000 players from 100+ competitions. The football data providers are the Data Sports Group (for standard stats) and StatsBomb (for advanced stats like xG).
Developing A Scouting Tool
The Data
The main advantage of professional scouting tools, as explained above, is that they have access to their own data, for as many leagues as possible. They can format and store it in any way they want. Because I work with open-source data from fbref.com, I was tied to their initial formatting and to the “Big 5 Leagues” with advanced stats – Premier League, La Liga, Ligue 1, Serie A, and Bundesliga. Moreover, although broad positional categories are given for players (i.e., forward or defender), specific positions (right winger, left back etc) are only given on a match-by-match basis. Thus, I had to come up with creative ways in which I could get general information about players. Here is what I did.
I collected the data for the “Big 5” leagues from fbref.com, as well as from FootballCritic, and Transfermarkt. FootballCritic was especially useful because it contained specific positions for each player, which I could then use when building a player profile. Transfermarkt had information such as market value, player height, player shirt number, joining date and contract expiration dates, which are incredibly useful when putting together the player bio. To mine all the data from Transfermarkt and FootballCritic I wrote several Python scripts which would get all the data for me and format it in a way that I found easy.
I assembled all this data into sets. Each league has a set of 11 csv files associated with it, containing standard and advanced stats, specific player positions, as well as physical and biographical data (date of birth, market value, contract duration, shirt number, height etc). While some of these files are not required to be updated (i.e., player positions or date of birth), the standard and advanced stats are updated after each gameweek.
I had to heavily curate the data, as there were a lot of discrepancies between the different sources. Here is how I did it:
- Duplicates were removed, as in some cases a player had played a small number of games before being transferred to his current club. Only a player’s current club is considered.
- Names were standardized throughout the data (i.e., accents are removed, addition of full names instead of nicknames etc).
- Positions were cross-referenced between the three websites to ensure correctness.
Removing accents from players’ names was the most difficult part – for this I also wrote a Python script. Some accents cannot be removed by standard decoders (like the “ð” character in Jóhann Berg Guðmundsson’s name), so I had to do it manually. Another major issue I faced was the usage of nicknames instead of names for players (prevalent in La Liga), or the addition / removal of middle names. Matching the names and ensuring everything was normalized across the board was done manually.
The Tool – developed in collaboration with FYP
Part of my day job is software development, so I have some experience with coding. I opted to develop the tool in C++, since I’m quite familiar with it and I like to have as much control as possible over the formatting. I developed the code from scratch using very simple algorithms and workflows. Below find the basic code blocks behind this tool:
- Create and build a “Player” object, which will hold all the information about the player (biographical and statistical).
- For every league, read the CSV files and add the relevant information to the “Player” object.
- For every statistical point, calculate the per 90 value (if necessary).
- Calculate the conversion factors between leagues and adjust the stats accordingly.
- Output the profiles of the Crystal Palace players.
- Ask the user if they would like to undertake a “Comparison” or “Similarity” search, and ask to input necessary parameters for the search.
- Display results and close program.
Let me elaborate a bit on points 4, 5, 6, and 7.
Point 4:
Since different leagues have different “strengths”, it would be safe to assume that statistical data points should be adjusted based on the league. For this I use the ELO ratings:

For example, if I were to compare a player from Premier League to La Liga, I would adjust the stats of the La Liga player as follows:
statLaLiga = statLaLiga – conversion factor * statLaLiga
where the conversion factor is:
(strengthPL – strengthLaLiga)/100
Point 5. The tool creates custom statistical profiles for all players in the 5 leagues. Once these profiles are built, the ones belonging to Crystal Palace players are written to specific player files. Building the profiles is very fast, ~ 1.14 seconds.
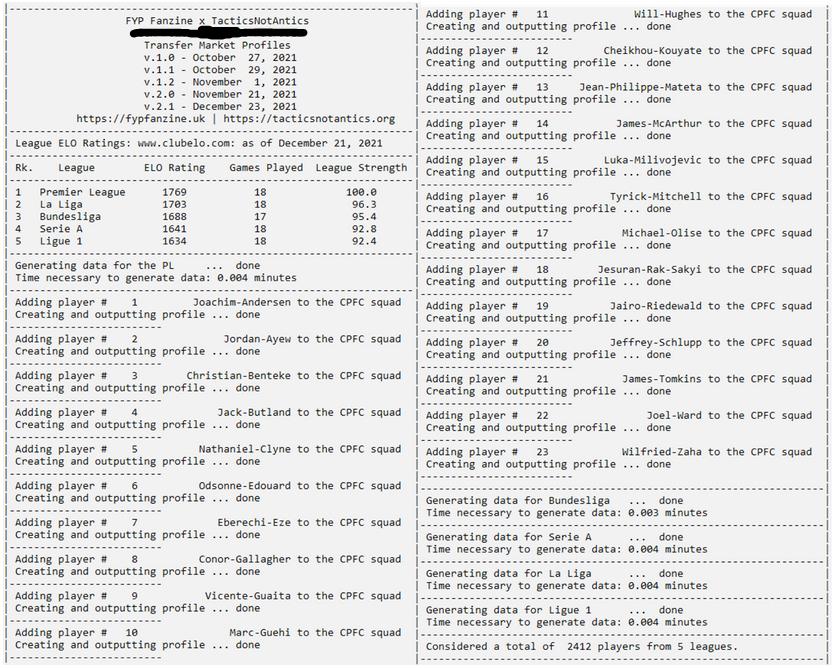

Below find how a player profile looks like, exemplified by Christian Benteke.

Points 6 and 7. It would be interesting to compare the performance of Palace players to those in the Premier League (or any other league for that matter). In this case, one can just choose the “Comparison” module (appears on screen, the user is required to input it from the keyboard). Several options appear, such as what Palace player would you like to use for comparison, the league in which you want to compare the player, and the minimum number of minutes for a player to be considered for comparison.
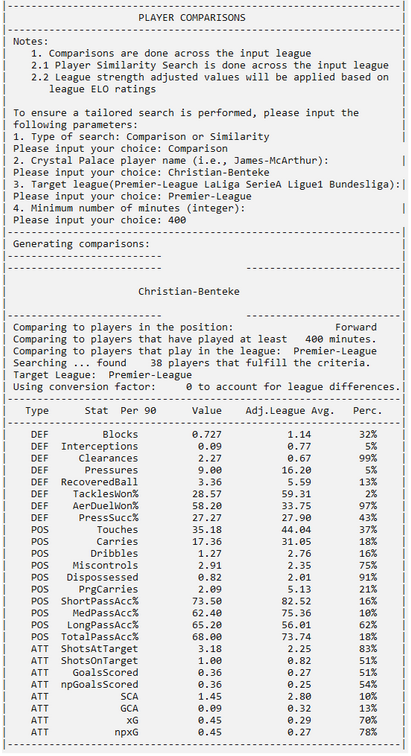
Key metrics are chosen for defending (DEF), possession and passing (POS), and attacking (ATT). The value of the Palace player is shown, along with the adjusted league average (see point 4 above), as well as the percentile in which the player is found.
If the Similarity module is desired, the user is presented with a few choices in terms of the search they would like to conduct. The search can be targeted (with preset values for key metrics) or comprehensive (where the entire player profile is considered). If the search is comprehensive, the user will be asked to input the maximum stat variance for all metrics. This parameter takes values from 0 to 1, which will then be converted internally to percentages.
For example, one can choose a 0.20 profile variance compared to the Crystal Palace player of interest. This means that, for example, if Christian Benteke has 5 touches in the opposition box per 90 minutes, a player will be considered “similar” to him if he has at most 20% less touches in the opposition box (in this case, 4). This algorithm is applied to all metrics considered.
Once a player is found for the particular search query, his information and comparison to the Crystal Palace player will be output (note: only one player is shown in the figures below to exemplify the output). At the end of the query, the tool will display how many players it considered for the comparison.
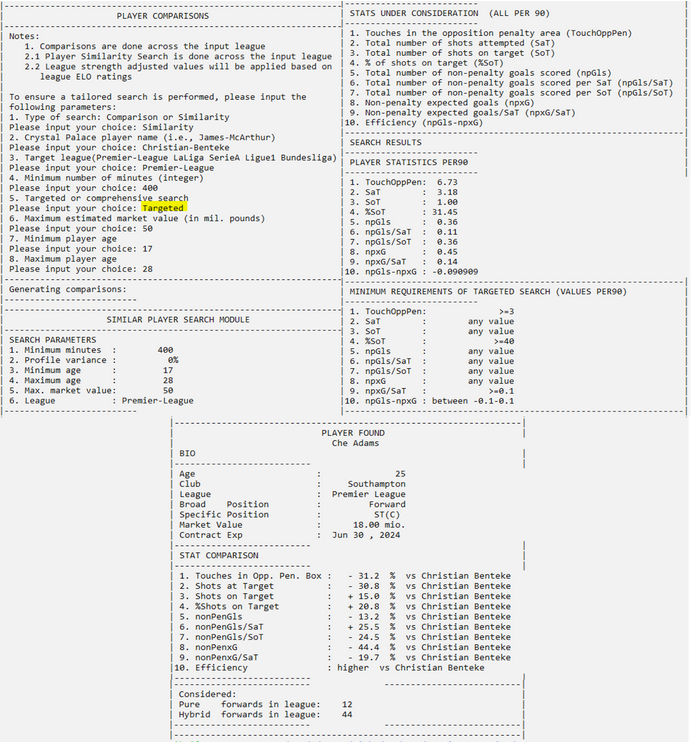
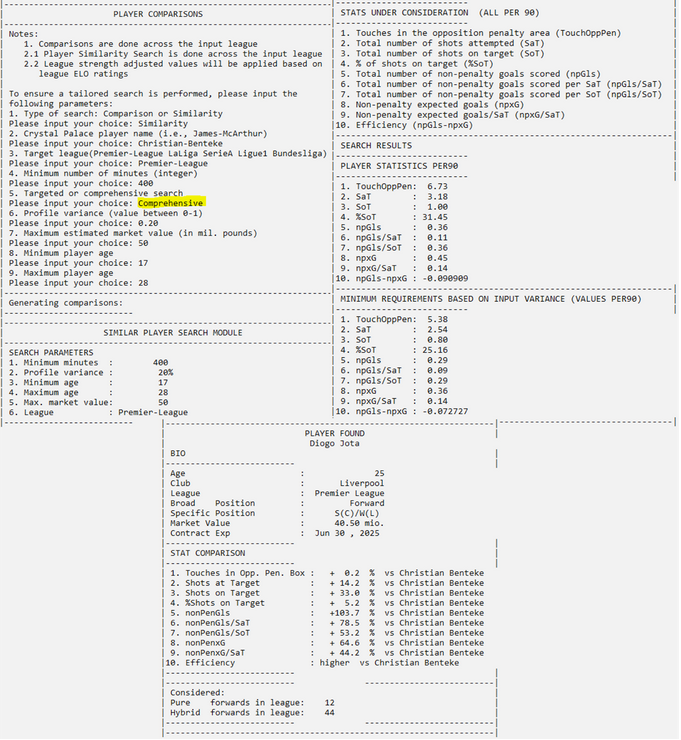
At the end of every search, a CSV file is written with the results. The file name structure is:
player_name + “_SimilarPlayers_” + query_league + “.csv”
Concluding Thoughts
What started as a sort of side-project turned into something much bigger. There is still a lot of work to do on this, as it’s currently in its alpha stage. Of course, you could ask why am I doing this, when you can compare players on fbref.com already? I did it because I wanted to have the full statistical profiles (including market values, bio data) available, the possibility of adjusting values over different leagues, and to tailor my searches to my needs. I also want to grow it steadily in the weeks/months to come and to make it available to the footballing community that cannot afford a professional scouting tool.
I’m a big fan of open-source code and of information being shared freely. This being said, I am not yet happy with all the results and I think I can improve the code significantly in the coming weeks. I also have to take care of some admin stuff, like finding a suitable open-source license to add to the code, creating a GitHub account etc. For this reason, I won’t yet make the code public, but should do so in the next few weeks.
Here are some things on my wishlist for the next few weeks:
- improve output formatting
- improve automation, as right now users have to write choices using the keyboard (perhaps a Python-based GUI)
- improve data curation, as part of it (too much for my liking) is manual
- write a detailed workflow on how to use the program
- add the possibility for users to choose their own stats for targeted comparison, as they are currently hard-coded.
Last Updated
[ratemypost]
[ratemypost-result]